Scientific research is a struggle with many wrong turns and lots of meticulous detail work. Then, after the Eureka moment, we reorder our ideas and write it all up in a nice clean and easy-to-follow paper.
If you just read papers, scientific research is a glorious activity, where the researcher is like a Zen master waiting for the right moment and then letting the arrow reach the target. Even in the case of Zen, reality is very different from what you see in the movies.
Therefore, scientists gather in conferences. Papers are given in formal presentations, to quickly communicate the final result of the research. However, the real action takes place in the hallways during the breaks and during meals. That is when the presenters are approached and war stories are exchanged.
The trick is to learn from other researcher's experience. It is like visiting the sausage factory so you know what to eat and most of all, what not to eat.
So here is the handout to our next conference presentation: HPL-2008-109.
For those not attending the conference, here is a trip report from the sausage factory.
HP used to have a literature distribution center in Campbell. It warehoused the brochures and other marketing collaterals for all currently shipping products. When sales representatives prepared an offer, they would order the pieces from Campbell and assemble the material in a booklet to present the customer.
Then HP bought Indigo. Now all those printed materials could be replaced by a document repository. The sales reps could "shop" for the required collaterals on a web site and the resulting document would be printed on demand on the Indigo press and finished, resulting in a professional booklet.
Our project built the prototype of this system called DPOD (I cannot recall what the acronym stands for). In alphabetic order, team included Hui Chao, Scott Clearwater, Anna Durante, Parag Joshi, Xiaofan Lin, Greg Nelson, Henry Sang, and Nick Saw.
We were not happy to build just a shopping cart solution as a front-end to a document management system. To maximize the document's impact, we implemented a custom printing system, also known as variable data printing system.
In the middle of the implementation, HP changed the colors in the corporate palette. To have a uniform look for all pieces in a marketing document, we had to automatically change the old corporate colors to the perceptually closest new colors.
Things could go particularly wrong with colored text on colored background. If in the old palette the text was readable, in the new palette it could become illegible. We had to check each foreground-background color pair for readability and then nudge one of the colors.
In the first prototype we did not yet have the code to parse the PDF and nudge the colors there. Instead, we ripped each page and fixed it pixel by pixel. To keep up with the Indigo's print speed, the implementation had to be very efficient. Yet, it also had to be very precise, so the nudged colors were consistent across the entire document.
My first implementation of the small color piece was colorimetric, i.e., I calculated ∆E94 differences and nudged the colors in cylindrical CIELAB coordinates before converting them back to sRGB.
In the second implementation, instead of enforcing a minimal ∆E distance, I enforced a lexical distance. I calculated the color name of the foreground and background colors and ensured there was at least one color name in-between.
Years before, at PARC, Maureen Stone had used the ISCC-NBS color naming system, so I looked for something different to implement.

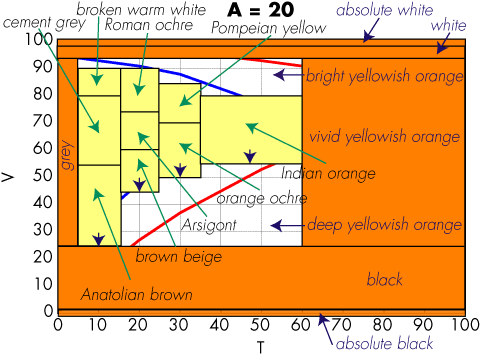
I found that most of the naming research in the literature was focused on the basic color terms, so I settled with the Coloroid color naming system. Here is how the leaf for hue A = 20 looks:

There are many white areas in the plot. In addition, to make things run fast, there is no time for gamut mapping, so the entire addressable color range must be tiled, for a resulting naming algorithm as follows:
The system worked so well, we made a follow-up for a product called MoD, for marketing on demand. It was a web service that would allow small and medium businesses (SMB) to create their own professional marketing collaterals. By "their own" we mean that instead of hiring an expensive graphic designer, they can get done a comparable collateral by an administrative assistant.
To avoid complexities like spec sheets for logos, we extended the color discrimination algorithms to work for any vector graphics element on a page. For example, the colored logo works on any background color from HP's corporate palette, as shown in these examples:





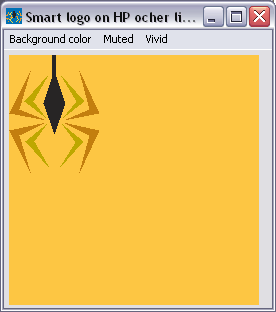


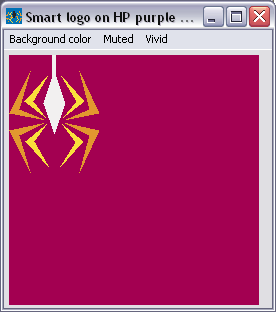

If we compare the web service to a minivan, then with our system we provided it with a racing car engine. Of course, from car manufacturers we learned that the buyer of a minivan hardly ever opens the hood, so there is no point in outfitting it with a racing engine, a lawn mover engine will do it. As my friend Irwin Sobel keeps telling me, the computer industry is learning fast from the US car manufacturer's cost-cutting strategies.
Now that you know what happened in the sausage factory you can read HPL-2008-109. Even better, come to the conference, where you can ask all your questions and learn from our experience.




No comments:
Post a Comment